Ik ben eerst zelf nog even goed gaan kijken, de bedoeling was:

- Zo_is_het 655 keer bekeken
Ombouwen naar:

- Zo_moet_het 658 keer bekeken
Maar het probleem is dat wanneer je honderd keer hetzelfde antwoord hebt, je een gigantische IF voorwaarde krijgt (honderd respondentnummers). We gebruiken nogal oude software, en dat trekt hij niet, dus zal je ze weer moeten ombouwen naar meerdere kleinere IF constructies.
En dat kan volgensmij véél makkelijker, hoe je ook zou kunnen nacoderen is:
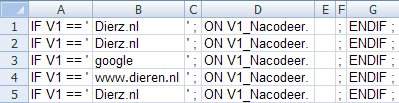
- Nieuw 654 keer bekeken
(hier is dus V1 een open vraag die gesteld wordt, en V1_Nacodeer een vraag 'achter de schermen' die we zelf vullen, in kolom E wordt hier een cijfer neergezet)
Even voor de duidelijkheid, de data die uit een onderzoek komt bestaat uit een heleboel regels, vol met cijfers en letters.
Aan het begin van elke regel staat een nummer, het respondentnummer. Bij nacoderen volgens de methode die we nu gebruiken (die ik eerder liet zien), wordt de data ook regel voor regel ingelezen. Elke keer komt hij bij een nieuwe regel, en dus respondent, en met de gegevens uit die regel (geslacht, leeftijd, antwoorden op de vragen, enz) kun je allemaal bewerkingen doen. Het nacodeer bestand is ook zo'n bewerking als je hem in het script zet.
Het is (denkik) veel makkelijker om wat er in het plaatje hierboven staat, te veranderen in:

- Nieuw2 654 keer bekeken
Ik gok zo dat dit makkelijker is dan wat ik hiervoor voorstelde. Misschien kan het zelfs handmatig? Waar ik heen wil is dat als er in kolom B iets staat wat ergens anders ook in kolom B voorkomt, hij de hele regel verwijderd, zodat je alleen unieke waardes overhoud voor kolom B.


